Create Preview Deployments on Forge with Laravel Harbor

Laravel Harbor is a CLI tool that allows you to quickly create on-demand preview environments for your app on Laravel Forge. Using this CLI, you can use GitHub actions to automatically deploy your branches when pull requests are created and tear down the deployment from your server when the pull request is merged. Here's an example of a provisioning workflow using GitHub actions (taken from the documentation):
name: preview-provision
on:
pull_request:
types: [opened, edited, reopened, ready_for_review]
jobs:
harbor-provision:
if: |
github.event.pull_request.draft == false &&
contains(github.event.pull_request.title, '[harbor]')
runs-on: ubuntu-latest
container:
image: kirschbaumdevelopment/laravel-test-runner:8.1
steps:
- name: Install Harbor via Composer
run: composer global require mehrancodes/laravel-harbor -q
- name: Start Provisioning
env:
FORGE_TOKEN: ${{ secrets.FORGE_API_TOKEN }}
FORGE_SERVER: ${{ secrets.FORGE_SERVER_ID }}
FORGE_GIT_REPOSITORY: ${{ github.repository }}
FORGE_GIT_BRANCH: ${{ github.head_ref }}
FORGE_DOMAIN: harbor.com
run: harbor provision
Once you've configured this CLI to run with GitHub actions, pull
requests will get updated comments with test environment details,
making it easy to see what your preview environment is for testing
a feature: 
Other features include:
- Seamless Forge integration
- Automated environment keys
- Ready for Laravel and Nuxt.js
- Flexible deployment scripts
- Customizable deployment workflows
- Enable SSR for Inertia
- Post-deployment actions:
- And more
To get started with Harbor and read the official docs, check out laravel-harbor.com. You'll need to have a Laravel Forge account as well; see Harbor's Prerequisites for details. Also, the CLI's source code is available on GitHub at mehrancodes/laravel-harbor if you want to check it out.
The post Create Preview Deployments on Forge with Laravel Harbor appeared first on Laravel News.
Join the Laravel Newsletter to get all the latest Laravel articles like this directly in your inbox.
Read more https://laravel-news.com/laravel-harbor
- Details
- Category: Dev News
Use the New Fluent Helper to Work With Multi-dimensional Arrays in Laravel 11.2

This week, the Laravel team released v11.2, which includes a
fluent() support helper, a context() helper, improved handling of a
missing database during a migrate operation, and
more.
Fluent Helper
Philo Hermans contributed a fluent()
helper function when working with multi-dimensional arrays. The
Fluent class has been in the Laravel framework for
quite a while; however, this PR introduces a helper convenience
method to create a fluent object instance:
$data = [
'user' => [
'name' => 'Philo',
'address' => [
'city' => 'Amsterdam',
'country' => 'Netherlands',
]
],
'posts' => [
[
'title' => 'Post 1',
],
[
'title' => 'Post 2',
]
]
];
collect($data)->get('user');
fluent($data)->user;
collect($data)->get('user')['name'];
fluent($data)->get('user.name');
collect(collect($data)->get('posts'))->pluck('title');
fluent($data)->collect('posts')->pluck('title');
json_encode(collect($data)->get('user')['address']);
fluent($data)->scope('user.address')->toJson();
Context Helper
Michael Nabil contributed a convenience
context() helper function for managing Context. Depending on the arguments passed, you
can either add to context, get the context object, or retrieve it
(with an optional custom default):
// Add user information to the context
context(['user' => auth()->user()]);
// Retrieve the context object
$context = context();
// Retrieve user information from the context
$user = context('user');
// Optional custom default value if not found.
$some_key = context('key_that_does_not_exist', false);
Default Value for Context Getters
Michael Nabil contributed support for a default value on Context getters:
// Before: Returns null if not found
Context::get('is_user');
Context::getHidden('is_user');
// After: Returns `false` if not found
Context::get('is_user', false); // false
Context::getHidden('is_user', false); // false
Context::get('is_user'); // null
Job Chain Test Assertion Methods
Günther Debrauwer contributed
assertHasChain() and
assertDoesntHaveChain() methods:
public function test_job_chains_foo_bar_job(): void
{
$job = new TestJob();
$job->handle();
$job->assertHasChain([
new FooBarJob();
]);
// $job->assertDoesntHaveChain();
}
Better database creation/wipe handling
Dries Vints contributed better database failure
handing (#50836) when running migrate when a
database isn't created yet, as well as updating the
migrate:fresh command to streamline the process when a
database does not exist #50838:
If the
migrate:freshcommand is called while there isn't any database created yet, it'll fail when it tries to wipe the database. This PR fixes this by first checking if the migrations table exists and if not, immediately go to the migrate command by skipping the db:wipe command. This will invoke the migrate command flow and subsequently will reach the point where the command will ask the user to create the database.In combination with #50836 this will offer a more seamless experience for people attempting to install Jetstream through the Laravel installer and choosing to not create the database.
The above description is taken from Pull Request #50838.
String Trim Removes Invisible Characters
Dasun Tharanga contributed an update to the framework
TrimStrings middleware, where invisible characters are
not trimmed during an HTTP request, which can cause issues when
submitting forms. See Pull Request #50832 for details.
Release notes
You can see the complete list of new features and updates below and the diff between 11.1.0 and 11.2.0 on GitHub. The following release notes are directly from the changelog:
v11.2.0
- [11.x] Fix: update
[@param](https://github.com/param)in some doc block by @saMahmoudzadeh in https://github.com/laravel/framework/pull/50827 - [11.x] Fix: update @return in some doc blocks by @saMahmoudzadeh in https://github.com/laravel/framework/pull/50826
- [11.x] Fix retrieving generated columns on legacy PostgreSQL by @hafezdivandari in https://github.com/laravel/framework/pull/50834
- [11.x] Trim invisible characters by @dasundev in https://github.com/laravel/framework/pull/50832
- [11.x] Add default value for
getandgetHiddenonContextby @michaelnabil230 in https://github.com/laravel/framework/pull/50824 - [11.x] Improves
serveArtisan command by @nunomaduro in https://github.com/laravel/framework/pull/50821 - [11.x] Rehash user passwords when logging in once by @axlon in https://github.com/laravel/framework/pull/50843
- [11.x] Do not wipe database if it does not exists by @driesvints in https://github.com/laravel/framework/pull/50838
- [11.x] Better database creation failure handling by @driesvints in https://github.com/laravel/framework/pull/50836
- [11.x] Use Default Schema Name on SQL Server by @hafezdivandari in https://github.com/laravel/framework/pull/50855
- Correct typing for startedAs and virtualAs database column definitions by @ollieread in https://github.com/laravel/framework/pull/50851
- Allow passing query Expression as column in Many-to-Many relationship by @plumthedev in https://github.com/laravel/framework/pull/50849
- [11.x] Fix
Middleware::trustHosts(subdomains: true)by @axlon in https://github.com/laravel/framework/pull/50877 - [11.x] Modify doc blocks for getGateArguments by @saMahmoudzadeh in https://github.com/laravel/framework/pull/50874
- [11.x] Add
[@throws](https://github.com/throws)to doc block for resolve method by @saMahmoudzadeh in https://github.com/laravel/framework/pull/50873 - [11.x] Str trim methods by @patrickomeara in https://github.com/laravel/framework/pull/50822
- [11.x] Add fluent helper by @PhiloNL in https://github.com/laravel/framework/pull/50848
- [11.x] Add a new helper for context by @michaelnabil230 in https://github.com/laravel/framework/pull/50878
- [11.x]
assertChainandassertNoChainon job instance by @gdebrauwer in https://github.com/laravel/framework/pull/50858 - [11.x] Remove redundant
getDefaultNamespacemethod in some classes (class, interface and trait commands) by @saMahmoudzadeh in https://github.com/laravel/framework/pull/50880 - [11.x] Remove redundant implementation of ConnectorInterface in MariaDbConnector by @saMahmoudzadeh in https://github.com/laravel/framework/pull/50881
- [11.X] Fix: error when using
orderByRawin query before usingcursorPaginateby @ngunyimacharia in https://github.com/laravel/framework/pull/50887
The post Use the New Fluent Helper to Work With Multi-dimensional Arrays in Laravel 11.2 appeared first on Laravel News.
Join the Laravel Newsletter to get all the latest Laravel articles like this directly in your inbox.
Read more https://laravel-news.com/laravel-11-2-0
- Details
- Category: Dev News
Event sourcing in Laravel with the Verbs package

Verbs is an Event Sourcing package for Laravel created by Thunk.dev. It aims to take all the good things about event sourcing and remove as much boilerplate and jargon as possible. Verbs allows you to derive the state of your application from the events that have occurred.
Learn about the history of Verbs
Here is an interview with Daniel Coulbourne, one of the creators of Verbs, that gives details on the project and why you might want to use Event Sourcing:
<iframe width="560" height="315" src="https://www.youtube.com/embed/asv-zcluV5Q?si=YY-gjZ-aSV3hpPaH&start=326" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>Verbs work great for the following...
- Applications that need to be auditable
- Applications whose schema may change over time
- Applications with complex business logic
What is Event Sourcing?
Instead of knowing just the current state of your app, every change (event) that leads to the current state is stored. This allows for a more granular understanding of how the system arrived at its current state and offers the flexibility to reconstruct or analyze the state at any point in time.
Learn more about Verbs
Visit the official Verbs documentation for complete details on the package, a Quickstart guide, and more.
The post Event sourcing in Laravel with the Verbs package appeared first on Laravel News.
Join the Laravel Newsletter to get all the latest Laravel articles like this directly in your inbox.
Read more https://laravel-news.com/event-sourcing-verbs
- Details
- Category: Dev News
Joomla 5.1.0 Release Candidate

The Joomla Project is pleased to announce the availability of Joomla 5.1 Release Candidate for testing.
What is this release for?
There are two main goals for Release Candidates:
- Providing developers with the basis to test their extensions and reporting any issues well before the final release
- Allowing users to discover the new features introduced to Joomla 5.1.
For a complete list of known backward compatibility issues for version 5.1, please see Potential backward compatibility issues in Joomla 5.1 on the documentation site.
What is this release NOT for?
This release candidate version of Joomla 5.1 is not suitable for production sites. It is for testing only.
Where to get it?
To always use the latest build of Joomla 5, we invite you to use the nightly build packages (updated every night).
To make it easier for newcomers, you can launch a free Joomla 5 website for testing at launch.joomla.org.
When is the final release due?
Joomla! 5.1 (general availability) will be released on or about 16th April 2024. The planned milestones are:
Alpha
- 28th November 2023 - done
- 26th December 2023 - done
- 23rd January 2024 - done
- 20th February 2024 - done
Beta (Feature Freeze)
- 5th March 2024 - done
- 19th March 2024 - done
Release Candidate (Language Freeze)
- 2nd April 2024 - this release
Stable Release
- 16th April 2024
Please note that dates may be subject to change depending on the availability of volunteers and circumstances beyond our control.
What’s new in Joomla 5.1 Release Candidate?
We are firmly committed to making the next generation of Joomla the best. These are the features that have been committed to version 5.1.
- All changes from 4.4 and 5.0
- Implement TUF updater (#42799)
- Heavily improve dark mode (#42986)
- Implement backend dark mode switch (#42221)
- Implement a Welcome Tour (#41659)
- SEO: Add trailing slash behaviour (#42702)
- SEO: Improve URL behaviour with index.php (#42704)
- Adding notice to global configuration for additional options in SEF plugin (#42832)
- Update Jooa11y Accessibility Checker Plugin with latest Sa11y (#42780)
- Improve Guided Tours with new features for required field handling and support for checkbox / radio / select lists as target (#40994)
- Add regex validation for fields (#42657)
- Add schema.org Generic type (#42699)
- Add schema.org Article type (#42402)
- Allow custom fields form be manipulates like category form (#42510)
- Replace bootstrap modal with new dialog in backend for
- Add main region and better support for modules in Cassiopeia error page (#42719)
- Joomla Update: Improving error handling when writing files (#41096)
- Update FontAwesome to 6.5.1 (#42721)
- Update TinyMCE to 6.8.3 (#42930)
- Strip attributes from images in HTML mails (#42448)
- Change type of field "value" in table #_fields_values from text to mediumtext (#42606)
- Add support for subcategory levels in contacts category view (#41618)
- Add “New Article” button to blog view (#39506)
- CLI Improvements
- Module conversion to service provider
- Add toolbar buttons in language installation toolbar to go directly to language management views (#42610)
- Improve long description output for templates (#42651)
- Add possibility to sort subform rows with buttons "up" and "down" (#42334)
- Add rebuild button in Tags (#42586)
- Improve uninstall of package children extension (#42607)
- Improve webservices filter (#42519)
- Improve webservice event classes (#42092)
- Use generic icon for documents in media manager (#42527)
- Rewrite com_associations in vanilla JS (#42771)
- Implementing Event classes for PageCache events (#41965)
- Fix actionlogs information emails containing HTML links (#40033)
- Load plugin group when executing batch tasks (#39013)
- Add Global Setting for Form Layout option to custom fields (#37320)
- Add SVG support to mod_banners (#41854)
- Several JS improvements (#42756, #42755, #42776, #42784)
- Update Code style fixer (#42603)
- Unit test for WebAsset (#42885)
As it's a release candidate, we now have a language freeze. From now on, no pull Requests touching the language files will be merged unless absolutely necessary (e.g., by fixing a critical bug). We’re two weeks away from a stable release, so the task is now: test, test, test.
We will not include any other new features in the 5.1 branch from now on. But you’re welcome to propose enhancements and fixes for existing features.
What are the plans for Joomla 5.1?
To learn more about our development strategy, please read this article.
How can you help Joomla 5.1 development?
To help ensure the 5.1 release and our major features are “production-ready”, we need your help testing releases and reporting any bugs you may find at issues.joomla.org.
We encourage extension developers to roll up their sleeves, seek out bugs and test their extensions with Joomla 5.1 and communicate their experience.
Where can I find documentation about Joomla 5?
There are some tutorials to help you with Joomla 5. You can find the existing ones, like creating a Plugin or a Module for Joomla 5, namespaces conventions, prepared statements, using the new web asset classes and many more in https://docs.joomla.org/Category:Joomla!_5.x
We encourage developers to help write the documentation about Joomla 5 on docs.joomla.org and manual.joomla.org to help and guide users and other extension developers.
A JDocs page will help developers to see the existing documentation and the documentation still needed.
We invite you to check it regularly, update it and provide the missing content.
Related information
If you are an extension developer, please make sure you subscribe to the extension developer channel https://joomlacommunity.cloud.mattermost.com/main/channels/extension-development-room
Where you can join the community of extension developers.
- Working with the Joomla Feature Tracker
- General developer mailing list
- Joomla developer network
- Joomla and UI framework
A Huge Thank You to Our Volunteers!
A big thank you goes out to everyone who contributed to the release!...
Read more https://www.joomla.org/announcements/release-news/5905-joomla-5-1-0-release-candidate.html
- Details
- Category: JAnnouncements
A Visit to Where the Cloud Touches the Ground
Hi there! I’m Zander Rose and I’ve recently started at Automattic to work on long-term data preservation and the evolution of our 100-Year Plan. Previously, I directed The Long Now Foundation and have worked on long-term archival projects like The Rosetta Project, as well as advised/partnered with organizations such as The Internet Archive, Archmission Foundation, GitHub Archive, Permanent, and Stanford Digital Repository. More broadly, I see the content of the Internet, and the open web in particular, as an irreplaceable cultural resource that should be able to last into the deep future—and my main task is to make sure that happens.
I recently took a trip to one of Automattic’s data centers to get a peek at what “the cloud” really looks like. As I was telling my family about what I was doing, it was interesting to note their perception of “the cloud” as a completely ephemeral thing. In reality, the cloud has a massive physical and energy presence, even if most people don’t see it on a day-to-day basis.
A trip to the cloud
Given the millions of sites hosted by Automattic, figuring out how all that data is currently served and stored was one of the first elements I wanted to understand. I believe that the preservation of as many of these websites as possible will someday be seen as a massive historic and cultural benefit. For this reason, I was thankful to be included on a recent meetup for WordPress.com’s Explorers engineering team, which included a tour of one of Automattic’s data centers.
The tour began with a taco lunch where we met amazing Automatticians and data center hosts Barry and Eugene, from our world-class systems and operations team. These guys are data center ninjas and are deeply knowledgeable, humble, and clearly exactly who you would want caring about your data.
The data center we visited was built out in 2013 and was the first one in which Automattic owned and operated its servers and equipment, rather than farming it out. By building out our own infrastructure, it gives us full control over every bit of data that comes in and out, as well as reduces costs given the large amount of data stored and served. Automattic now has a worldwide network of 27 data centers that provide both proximity and redundancy of content to the users and the company itself.
The physical building we visited is run by a contracted provider, and after passing through many layers of security both inside and outside, we began the tour with the facility manager showing us the physical infrastructure. This building has multiple customers paying for server space, with Automattic being just one of them. They keep technical staff on site that can help with maintenance or updates to the equipment, but, in general, the preference is for Automattic’s staff to be the only ones who touch the equipment, both for cost and security purposes.
The four primary things any data center provider needs to guarantee are uninterruptible power, cooling, data connectivity, and physical security/fire protection. The customer, such as Automattic, sets up racks of servers in the building and is responsible for that equipment, including how it ties into the power, cooling, and internet. This report is thus organized in that order.
Power
On our drive in, we saw the large power substation positioned right on campus (which includes many data center buildings, not just Automattic’s). Barry pointed out this not only means there is a massive amount of power available to the campus, but it also gets electrical feeds from both the east and west power grids, making for redundant power even at the utility level coming into the buildings.

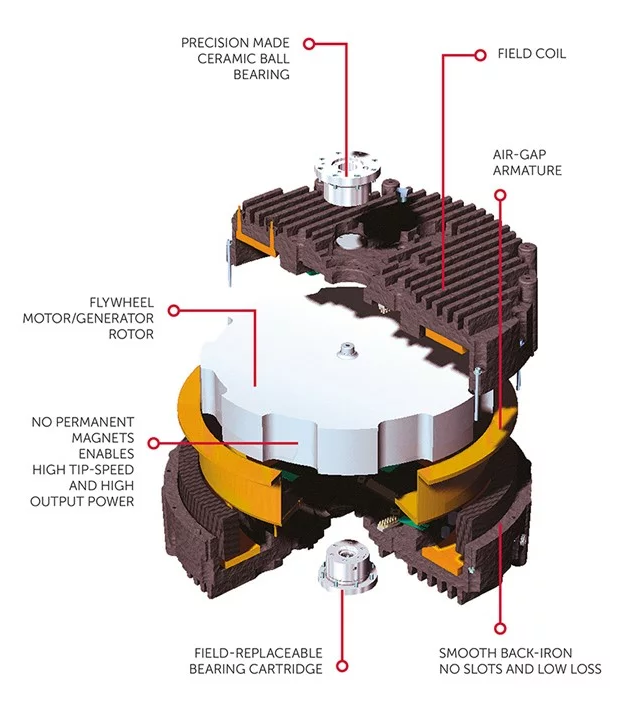
One of the more unique things about this facility is that instead of battery-based instant backup power, it uses flywheel storage by Active Power. This is basically a series of refrigerator-sized boxes with 600-pound flywheels spinning at 10,000 RPM in a vacuum chamber on precision ceramic bearings. The flywheel acts as a motor most of the time, getting fed power from the network to keep it spinning. Then if the power fails, it switches to generator mode, pulling energy out of the flywheel to keep the power on for the 5-30 seconds it takes for the giant diesel generators outside to kick in.
Those generators are the size of semi-truck trailers and supply four megawatts each, fueled by 4,500-gallon diesel tanks. That may sound like a lot, but that basically gives them 48 hours of run time before needing more fuel. In the midst of a large disaster, there could be issues with road access and fuel shortages limiting the ability to refuel the generators, but in cases like that, our network of multiple data centers with redundant capabilities will still keep the data flowing.
Cooling
Depending on outside ambient temperatures, cooling is typically around 30% of the power consumption of a data center. The air chilling is done through a series of cooling units supplied by a system of saline water tanks out by the generators.
Barry and Eugene pointed out that without cooling, the equipment will very quickly (in less than an hour) try to lower their power consumption in response to the heat, causing a loss of performance. Barry also said that when they start dropping performance radically, it makes it more difficult to manage than if the equipment simply shut off. But if the cooling comes back soon enough, it allows for faster recovery than if hardware was fully shut off.
Handling the cooling in a data center is a complicated task, but this is one of the core responsibilities of the facility, which they handle very well and with a fair amount of redundancy.
Data connectivity
Data centers can vary in terms of how they connect to the internet. This center allows for multiple providers to come into a main point of entry for the building.
Automattic brings in at least two providers to create redundancy, so every piece of equipment should be able to get power and internet from two or more sources at all times. This connectivity comes into Automattic’s equipment over fiber via overhead raceways that are separate from the power and cooling in the floor. From there it goes into two routers, each connected to all the cabinets in that row.
Server area
As mentioned earlier, this data center is shared among several tenants. This means that each one sets up their own last line of physical security. Some lease an entire data hall to themselves, or use a cage around their equipment; some take it even further by obscuring the equipment so you cannot see it, as well as extending the cage through the subfloor another three feet down so that no one could get in by crawling through that space.

Automattic’s machines took up the central portion of the data hall we were in, with some room to grow. We started this portion of the tour in the “office” that Automattic also rents to both store spare parts and equipment, as well as provide a quiet place to work. On this tour it became apparent that working in the actual server rooms is far from ideal. With all the fans and cooling, the rooms are both loud and cold, so in general you want to do as much work outside of there as possible.
What was also interesting about this space is that it showed all the generations of equipment and hard drives that have to be kept up simultaneously. It is not practical to assume that a given generation of hard drives or even connection cables will be available for more than a few years. In general, the plan is to keep all hardware using identical memory, drives, and cables, but that is not always possible. As we saw in the server racks, there is equipment still running from 2013, but these will likely have to be completely swapped in the near future.
Barry also pointed out that different drive tech is used for different types of data. Images are stored on spinning hard drives (which are the cheapest by size, but have moving parts so need more replacement), and the longer lasting solid state disk (SSD) and non-volatile memory (NVMe) technology are used for other roles like caching and databases, where speed and performance are most important.

Barry explained that data at Automattic is stored in multiple places in the same data center, and redundantly again at several other data centers. Even with that much redundancy, a further copy is stored on an outside backup. Each one of the centers Automattic uses has a method of separation, so it is difficult for a single bug to propagate between different facilities. In the last decade, there’s only been one instance where the outside backup had to come into play, and it was for six images. Still, Barry noted that there can never be too many backups.
An infrastructure for the future
And with that, we concluded the tour and I would soon head off to the airport to fly home. The last question Barry asked me was if I thought this would all be around in 100 years. My answer was that something like it most certainly will, but that it would look radically different, and may be situated in parts of the world with more sustainable cooling and energy, as more of the world gets large bandwidth connections.
As I thought about the project of getting all this data to last into the deep future, I was very impressed by what Automattic has built, and believe that as long as business continues as normal, the data is incredibly safe. However, on the chance that things do change, I think developing partnerships with organizations like The Internet Archive, Permanent.org, and perhaps national libraries or large universities will be critically important to help make sure the content of the open web survives well into the future. We could also look at some of the long-term storage systems that store data without the need for power, as well as systems that cannot be changed in the future (as we wonder if AI and censorship may alter what we know to be “facts”). For this, we could look at stable optical systems like Piql, Project Silica, and Stampertech. It breaks my heart to think the world would have created all this, only for it to be lost. I think we owe it to the future to make sure as much of it as possible has a path to survive.

Read more https://wordpress.com/blog/2024/04/01/data-center-visit/
- Details
- Category: Dev News
- 5 Hidden Features of WordPress.com
- Hot Off the Press: New WordPress.com Themes for March 2024
- Cache Routes with Cloudflare in Laravel
- Learn how to manage timezones in your Laravel Apps
- "Can I PHP?" Raycast Extension
- WordPress Block Themes Explained in 250 Seconds
- Introducing the Context Facade in Laravel
Page 5 of 1308